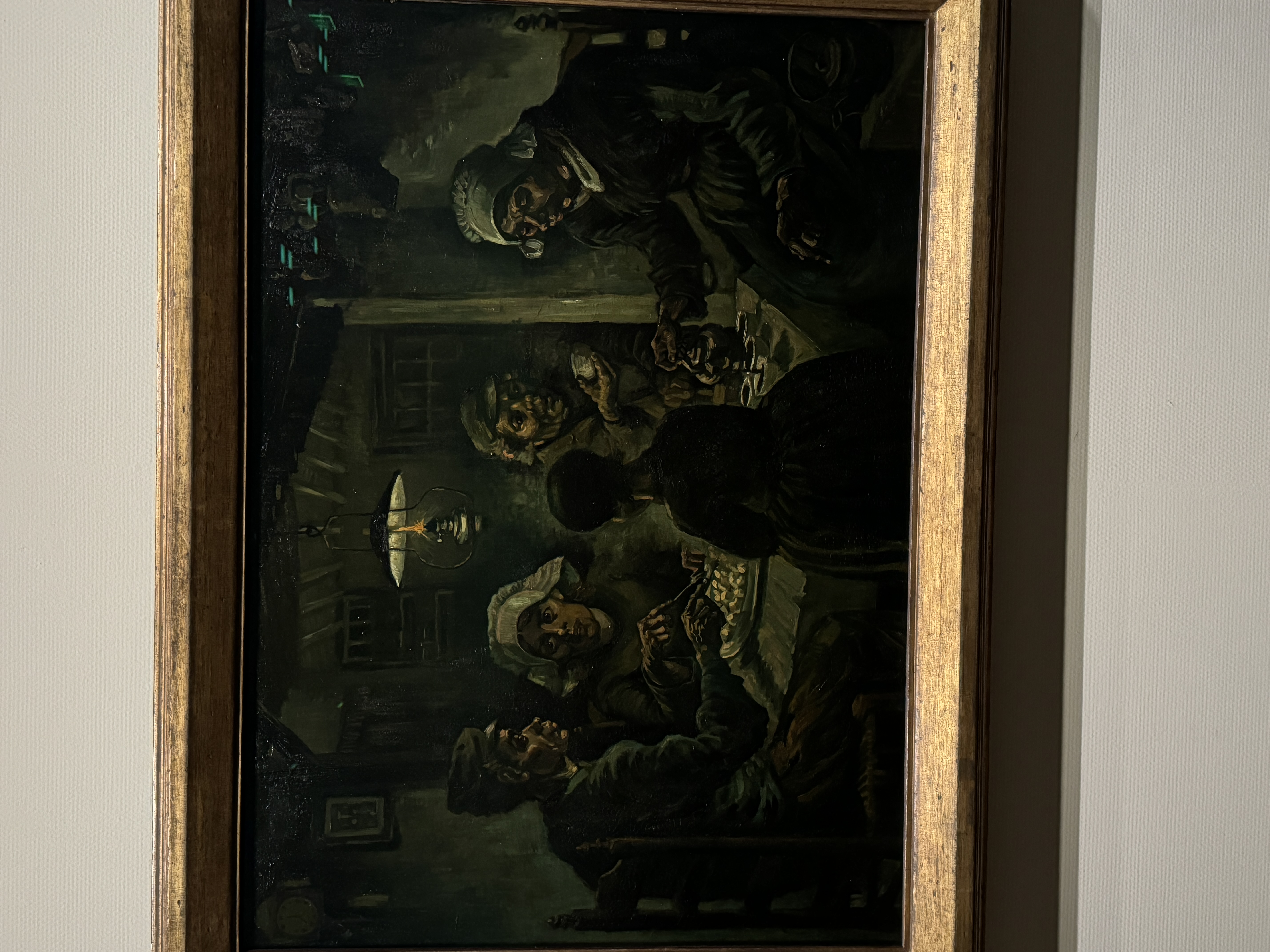Yilin Wang
Research Scientist at Adobe, San Jose
I work on multimodal generative models, instruction-based image editing, and production model quality at Adobe. My recent work connects post-training, reinforcement learning, evaluation, and product deployment for image generation/editing systems. I have contributed to 8 tech transfers across Photoshop, Lightroom, and Adobe Firefly, and hold 46 US patents.
Delivery & Tech Transfer Highlights

Firefly Image 5
Firefly Image 5 is an instruction-based image generation and image editing model — enabling precise, natural-language-driven edits at production quality.
Select People Details
Automatically detects and selects individuals and specific details — hair, skin, clothing, facial features, hands — in an image, enabling highly precise individual or group editing.

Object Finder
Part of the Photoshop Object Selection Tool, Object Finder uses AI to automatically identify and select objects — people, items, sky, and more — across the entire image.
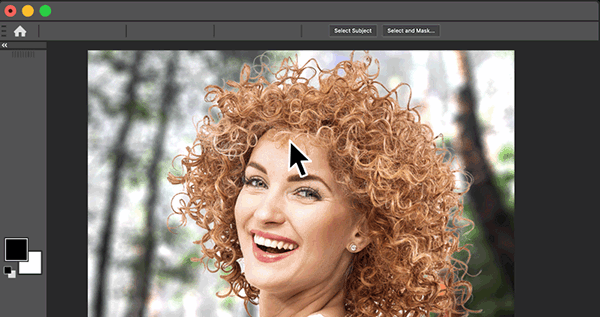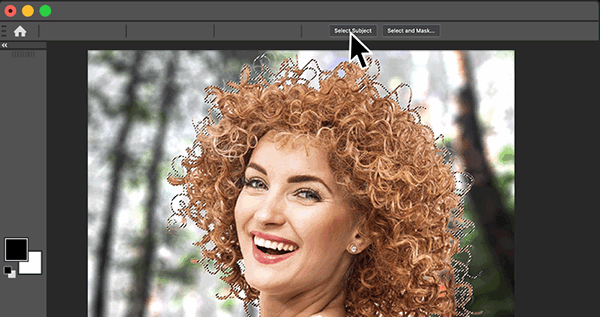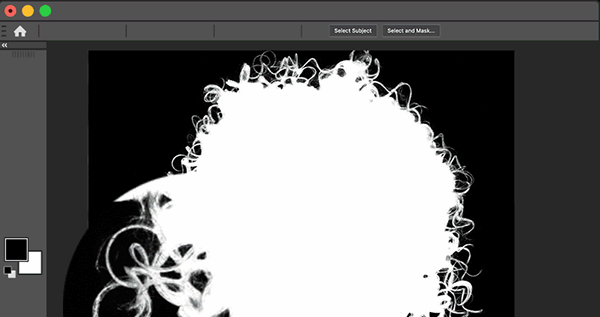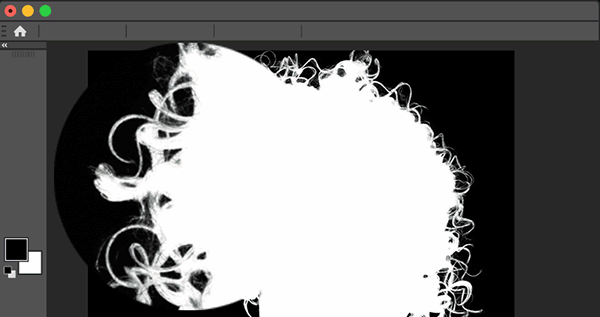
Select Subject
Leverages AI to isolate the primary subject of an image with a single click — delivering fast, accurate one-click selections for photographers and designers.
Highlighted Research
I strive for simple yet scalable methods in image understanding and editing. Representative works are highlighted below. Full list on Google Scholar.

OmniStyle2: Learning to Stylize by Learning to Destylize
ECCV 2026A scalable supervised style-transfer paradigm that learns to destylize real artworks, creating authentic pixel-aligned training pairs for high-fidelity stylization.
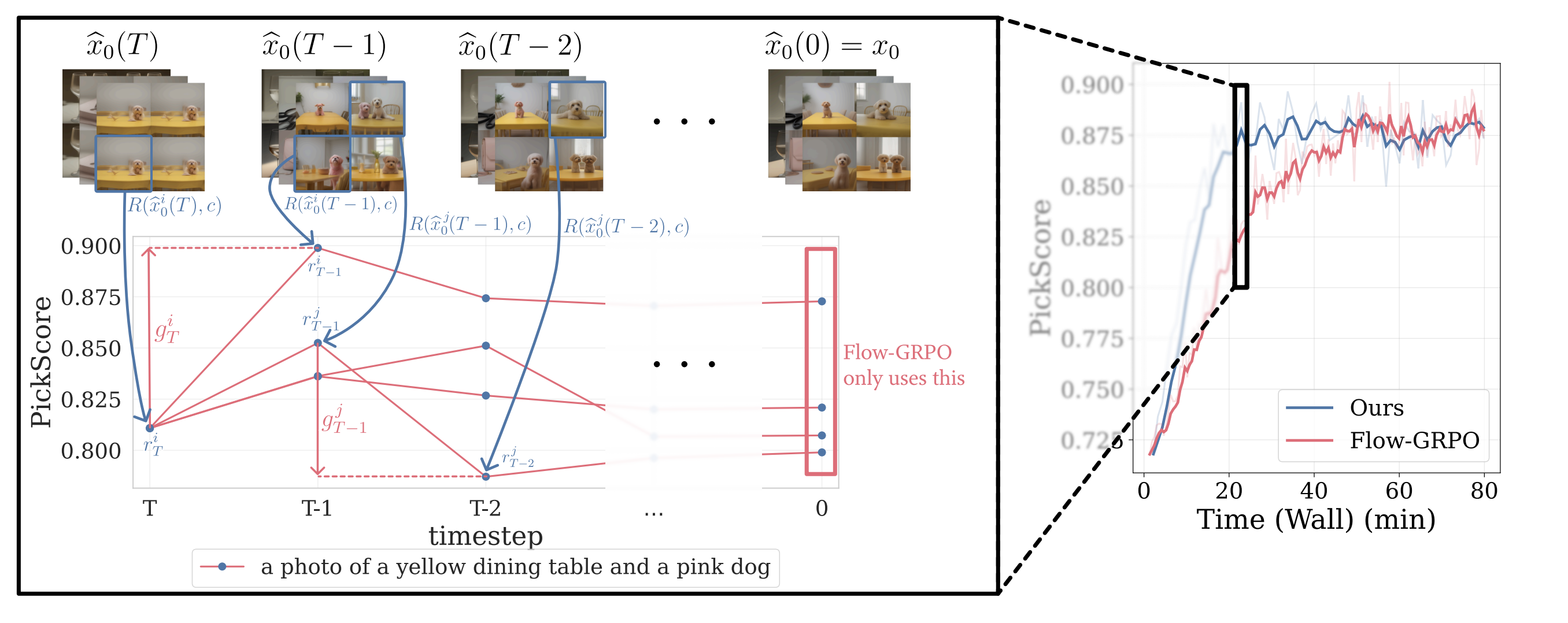
Stepwise Credit Assignment for GRPO on Flow-Matching Models
CVPR 2026We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement.

Relational Visual Similarity
CVPR 2026We introduce a new visual similarity notion: relational visual similarity (relsim), which complements traditional attribute similarity (e.g., LPIPS, CLIP, DINO).
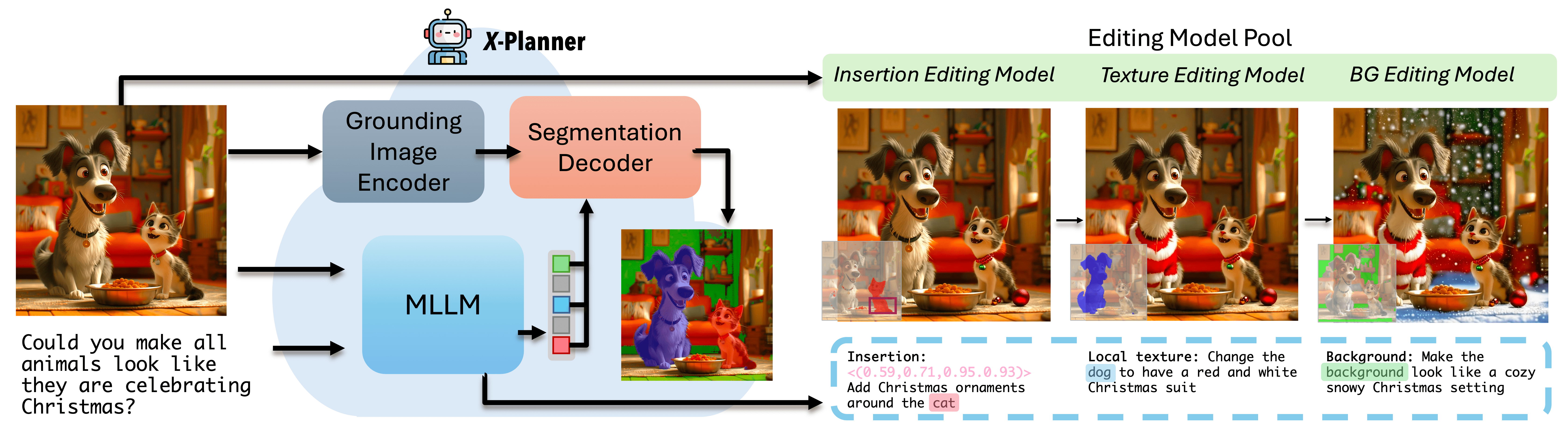
Beyond Simple Edits: X-Planner for Complex Instruction-Based Image Editing
AAAI 2026An MLLM-based planning system that bridges user intent with editing model capabilities.

OmniStyle: Filtering High Quality Style Transfer Data at Scale
CVPR 2025First end-to-end style transfer framework on DiT, achieving 1K-resolution stylization with the OmniStyle-1M dataset. Supports both instruction- and image-guided stylization.

FINECAPTION: Compositional Image Captioning
CVPR 2025A unified VLM for free-form mask grounding and compositional captioning.

UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
ICLR 2025 (Highlight)Foundational multi-modal generative model — A universal framework for image generation and editing by treating input/output images as video frames, learning real-world dynamics from video supervision.

SigStyle: Signature Style Transfer via Personalized Text-to-Image Models
AAAI 2025Style-preserved transfer via personalized subject editing diffusion model.

SwapAnything: Enabling Arbitrary Object Swapping in Personalized Visual Editing
ECCV 2024Personalized subject-driven image editing with arbitrary object swapping.

UniHuman: A Unified Model for Editing Human Images in the Wild
CVPR 2024Human editing via diffusion.
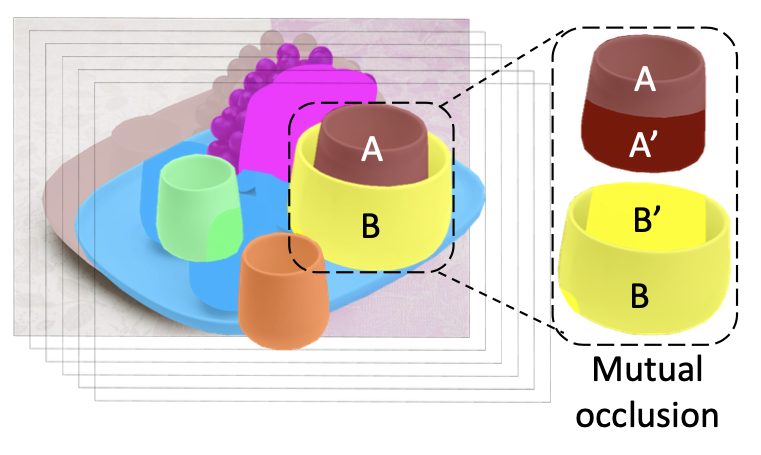
Amodal Scene Analysis via Holistic Occlusion Relation Inference and Generative Mask Completion
AAAI 2024 (oral)Amodal segmentation with mutual occlusion reasoning.

PHOTOSWAP: Personalized Subject Swapping in Images
NeurIPS 2023Personalized subject-driven image editing.

LightPainter: Interactive Portrait Relighting with Freehand Scribble
CVPR 2023Scribble-based interactive portrait relighting system.

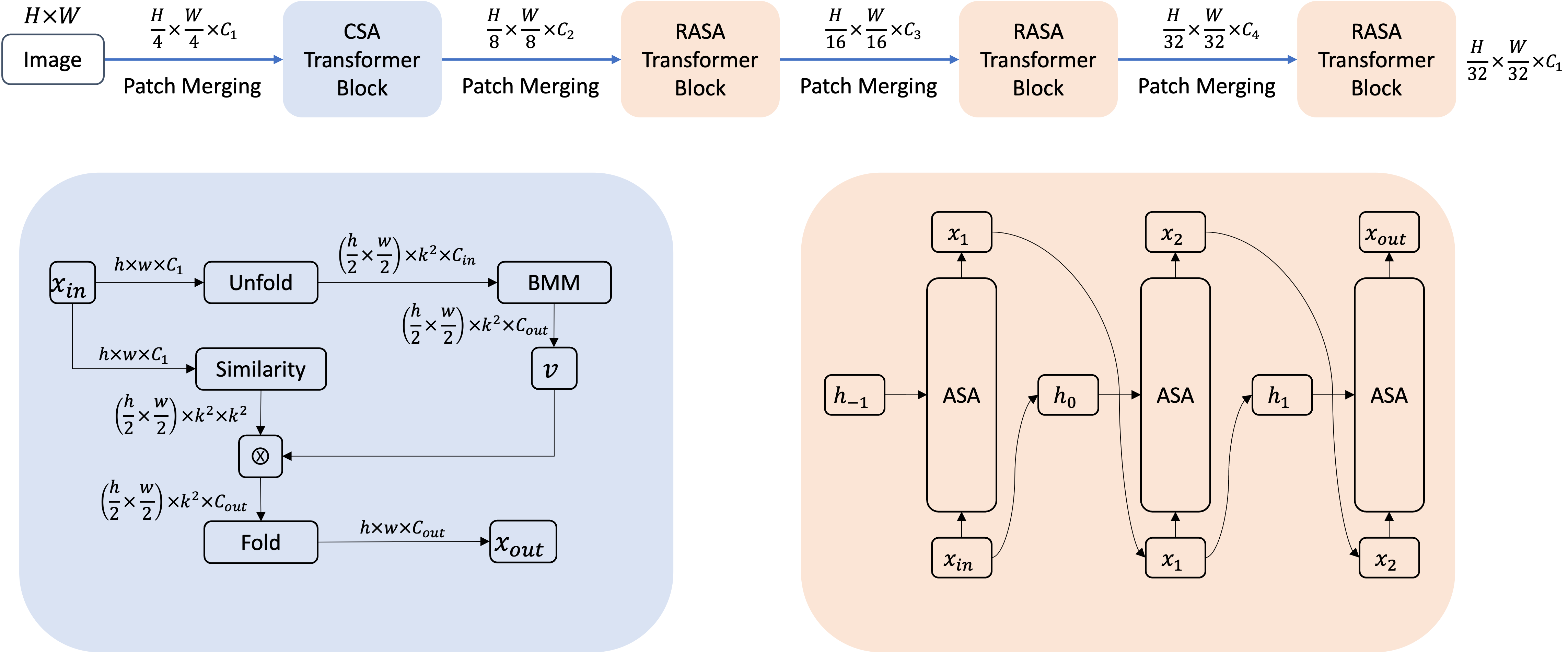
Lite Vision Transformer with Enhanced Self-Attention
CVPR 2022Light-weight vision transformer models for vision tasks.
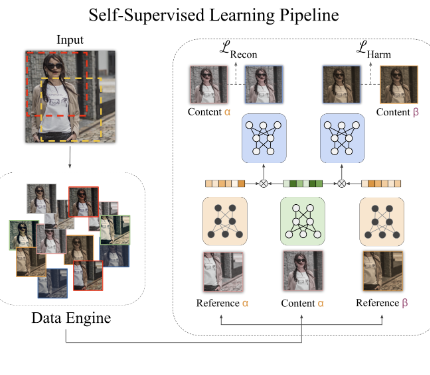
SSH: A Self-Supervised Framework for Image Harmonization
ICCV 2021Image harmonization based on self-supervised learning.

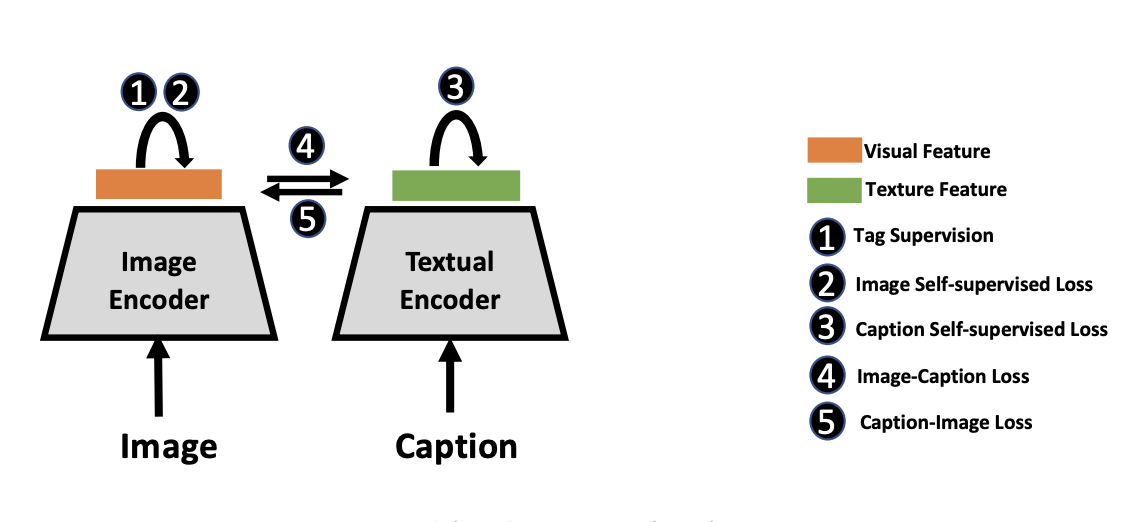
Multimodal Contrastive Training for Visual Representation Learning
CVPR 2021Intra- and inter-modal similarity preservation for multimodal representation learning.
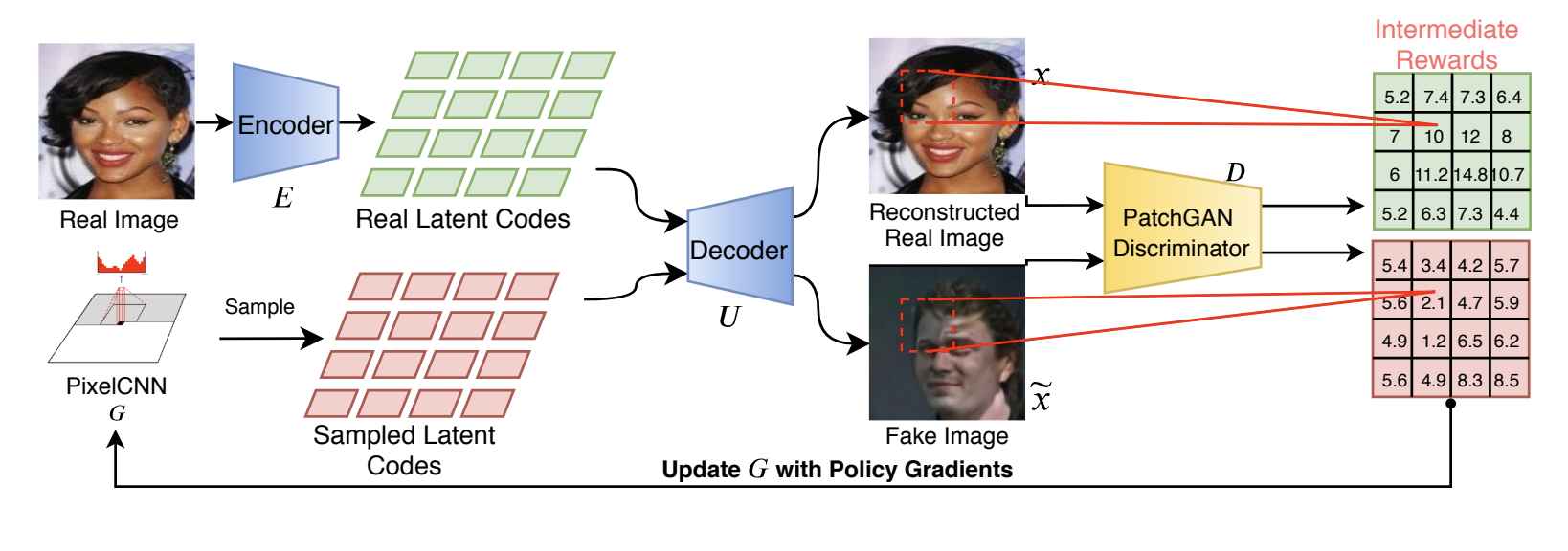
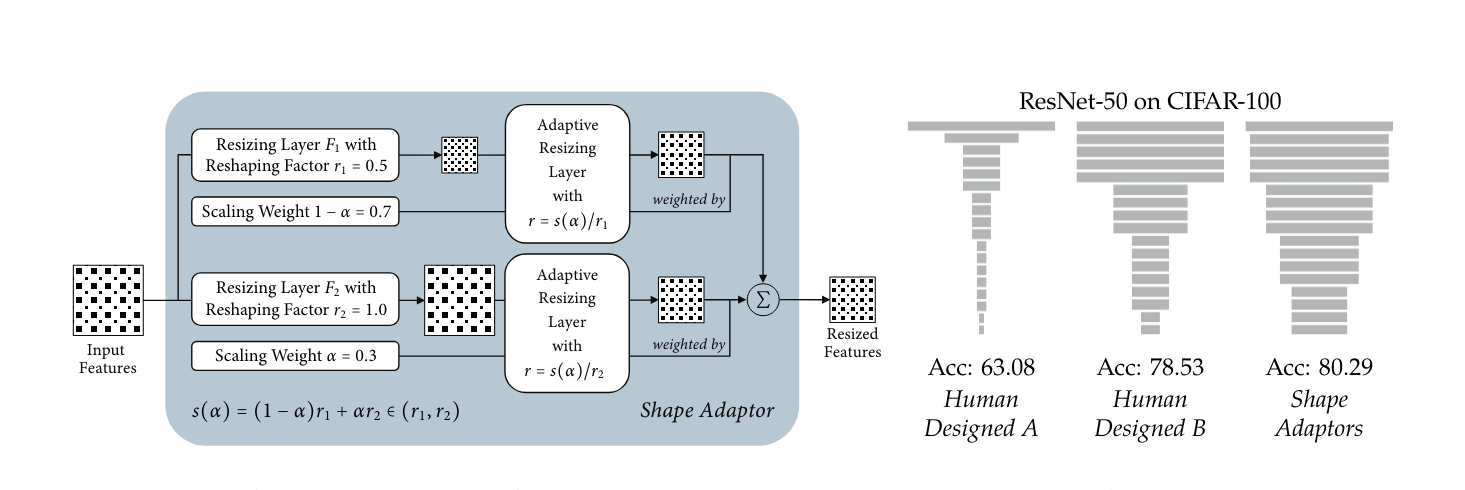

PhD Research

2018
- Generalizing Graph Matching beyond Quadratic Assignment Model
Tianshu Yu, Junchi Yan, Yilin Wang, Wei Liu, Baoxin Li
NeurIPS 2018 - Weakly Supervised Facial Attribute Manipulation via Deep Adversarial Network
Yilin Wang, Suhang Wang, Guojun Qi, Jiliang Tang, Baoxin Li
WACV 2018 [paper] - CrossFire: Cross Media Joint Friend and Item Recommendations
Kai Shu, Suhang Wang, Jiliang Tang, Yilin Wang, Huan Liu
WSDM 2018 spotlight [paper] - Understanding and Predicting Delay in Reciprocal Relations
Jundong Li, Jiliang Tang, Yilin Wang, Yali Wan, Yi Chang, Huan Liu
WWW 2018 Research Track [arXiv] - Exploring Hierarchical Structures for Recommender Systems
Suhang Wang, Jiliang Tang, Yilin Wang, Huan Liu
IEEE TKDE
2017
- CLARE: A Joint Approach to Label Classification and Tag Recommendation
Yilin Wang, Suhang Wang, Jiliang Tang, Guojun Qi, Huan Liu, Baoxin Li
AAAI 2017 oral [paper] [code] - Understanding and Discovering Deliberate Self-harm Content in Social Media
Yilin Wang, Jiliang Tang, Jundong Li, Baoxin Li, Yali Wan, Clayton Mellina, Neil O'Hare, Yi Chang
WWW 2017 Research Track [paper] [slides] - Exploiting Hierarchical Structures for Unsupervised Feature Selection
Suhang Wang, Yilin Wang, Jiliang Tang, Charu Aggarwal, Suhas Ranganath, Huan Liu
SDM 2017 [paper] - What Your Images Reveal: Exploiting Visual Contents for Point-of-Interest Recommendation
Suhang Wang, Yilin Wang, Jiliang Tang, Kai Shu, Suhas Ranganath, Huan Liu
WWW 2017 Research Track [paper]
2016
- PPP: Joint Pointwise and Pairwise Image Label Prediction
Yilin Wang, Suhang Wang, Jiliang Tang, Huan Liu, Baoxin Li
CVPR 2016 [paper] - Efficient Unsupervised Abnormal Crowd Activity Detection Based on a Spatiotemporal Saliency Detector
Yilin Wang, Qiang Zhang, Baoxin Li
WACV 2016 [paper] [code] - Scale Adaptive Eigen Eye for Fast Eye Detection in Wild Web Images
Xu Zhou, Yilin Wang, Peng Zhang, Baoxin Li
ICIP 2016
2015
- Sentiment Analysis for Social Media Images
Yilin Wang, Baoxin Li
ICDM PhD Forum 2015 - Real Time Vehicle Back-up Warning System with Single Camera
Yilin Wang, Jun Cao, Baoxin Li
ICIP 2015 [paper] - Unsupervised Sentiment Analysis for Social Media Images
Yilin Wang, Suhang Wang, Jiliang Tang, Huan Liu, Baoxin Li
IJCAI 2015 [paper] [project] - Inferring Sentiment from Web Images with Joint Inference on Visual and Social Cues: A Regulated Matrix Factorization Approach
Yilin Wang, Yuheng Hu, Subbarao Kambhampati, Baoxin Li
ICWSM 2015 oral [paper] - Structure Preserving Image Quality Assessment
Yilin Wang, Qiang Zhang, Baoxin Li
ICME 2015 oral [paper] - Exploring Implicit Hierarchical Structure for Recommender Systems
Suhang Wang, Jiliang Tang, Yilin Wang, Huan Liu
IJCAI 2015 [paper] - Improving Vision-based Self-positioning in Intelligent Transportation Systems via Integrated Lane and Vehicle Detection
Parag S. Chandakkar, Yilin Wang, Baoxin Li
WACV 2015 [paper]
2014
- Image Co-segmentation via Multi-task Learning
Qiang Zhang, Jiayu Zhou, Yilin Wang, Jieping Ye, Baoxin Li
BMVC 2014 [paper]
Service & Interns
- Area Chair: ACM MM 2020, 2021
- Reviewer: CVPR, ICCV, ECCV, ICML, NeurIPS (since 2017)
- Interns collaborated with: Zhanghan Ke, Nannan Li, Yiqun Mei, Yulun Zhang, Shikun Liu, Chenglin Yang, Jeya Maria Jose Valanarasu, Kenan E Ak, Qihang Yu, Xin Yuan, Yifan Jiang, Jing Gu, Zhibo Yang
Misc
I am on a journey to travel around the world and see as many Van Gogh paintings as possible in person. Below are some shots from my visits.